AI Agent 做得越深,越不能只留下最后答案。一个客服回复、一次合同初审、一条客户状态更新,如果后面出了问题,团队需要知道它用了哪些资料、调用了哪些工具、谁确认过、最终写入了什么。
这就是证据链。它和 质量门禁、审批队列、失败回放样本库 是一套东西:不是为了把流程做复杂,而是让 Agent 的每一步都能复盘。
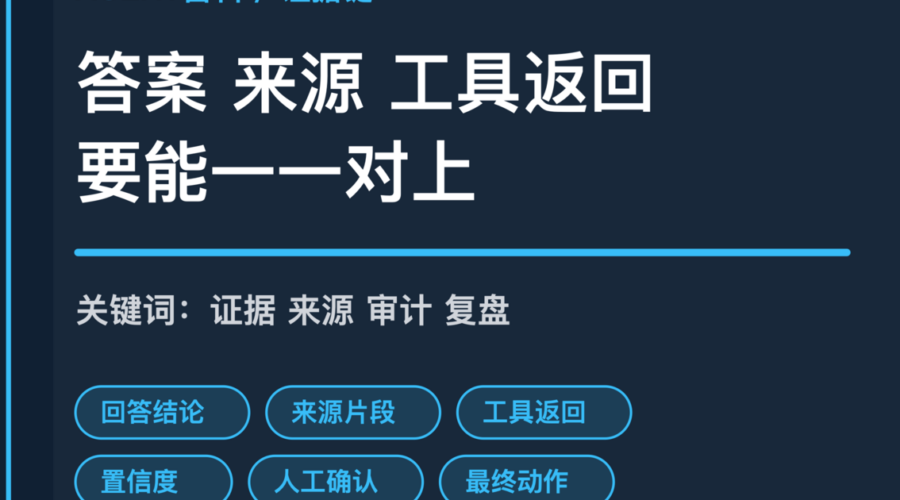
先把答案拆成结论和依据
很多 Agent 日志只记录“回答了什么”,却没有记录“为什么这样回答”。这会导致复盘时只能猜:是知识库命中了旧资料,还是工具返回为空,或者模型自己补了一段看似合理的内容。
更稳的做法是把答案拆成两层:第一层是面向用户的结论,第二层是内部证据,包括来源文档、引用片段、工具返回、时间戳和置信度。用户不一定要看到全部证据,但系统要留得住。
工具返回要保留原始结果
工具调用很容易被摘要吞掉。比如 Agent 查询 CRM 后只写“客户状态正常”,但原始返回里可能还有欠费、投诉、合同到期这些字段。只留摘要,后面就很难判断是工具没查到,还是 Agent 没读懂。
所以关键工具返回要保留原始字段和裁剪后的可读摘要。前面写过 数据血缘说明,这里的逻辑相同:结论要能追到原始来源。
人工确认也要进入链路
人工确认不是一句“已确认”就够了。谁确认、确认了什么、有没有修改、为什么放行或拒绝,都应该进入证据链。否则出现争议时,审批环节反而会变成新的盲区。
对于高风险动作,证据链里还要记录执行前后的状态差异。比如修改权限前是什么权限,修改后是什么权限,是否设置了有效期,回滚入口在哪里。
证据链不等于无限存储
证据链也要克制。不是所有聊天都永久保存,也不是每个中间 token 都要落库。更现实的做法,是按风险分级:普通问答保留来源和摘要,高风险写入保留完整工具返回和人工确认,事故样本进入回放库。
这可以接上 SLA 分层。任务越高风险、越影响业务系统,证据链就应该越完整。
总结
AI Agent 证据链的核心,是让答案、来源、工具返回、人工确认和最终动作能互相对上。它不只是审计材料,也是后续优化提示词、知识库和工具权限的基础。